SuperBench大模型综合能力评测报告
在人工智能的浪潮中,大模型的能力如何影响我们的未来?SuperBench的评测报告为我们揭开了哪些关键点?2023年,当模型的安全性和价值观评估成为焦点,我们又该如何确保AI的可持续发展?今天,让我们一起探索大模型的智能边界,解读它们在语义理解、代码编写、智能体表现等方面的最新进展。
太侠今天分享的是《SuperBench大模型综合能力评测报告》,来源:SuperBench团队。
报告概要:
SuperBench团队在2024年3月发布了一份详尽的评测报告,深入分析了大模型在多个维度上的能力。报告涵盖了从2018年至2023年大模型能力的迁移历程,突出了语义理解、代码编写、对齐、智能体和安全等关键领域的进展。
评测原则强调了开放性、动态性、科学性和权威性,旨在为大模型提供一个客观、科学的评价标准。
报告目录:
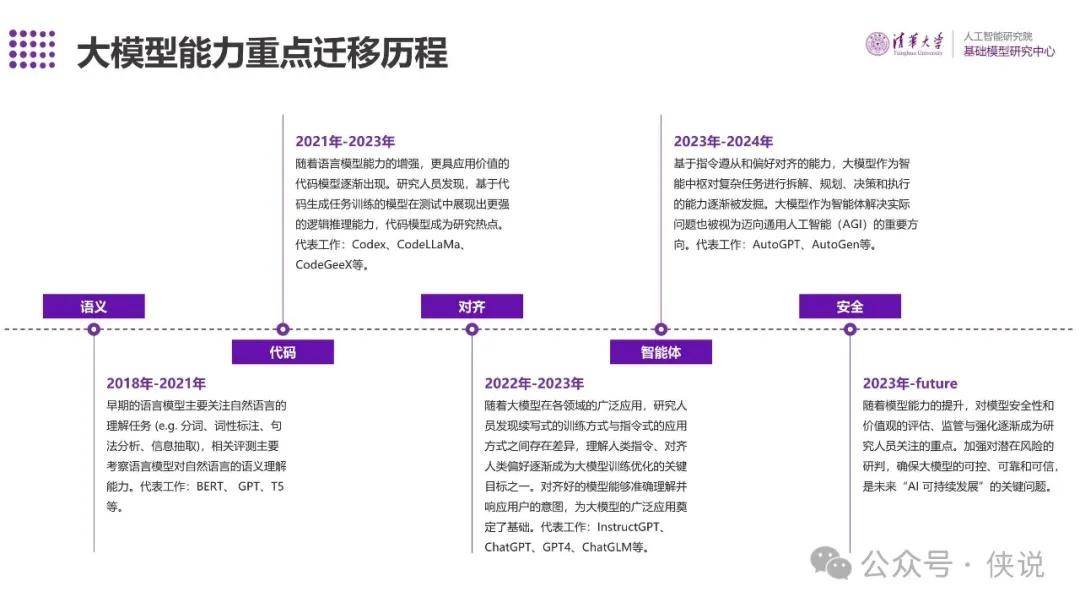
大模型能力重点迁移历程
大模型评测原则标准
SuperBench评测模型列表
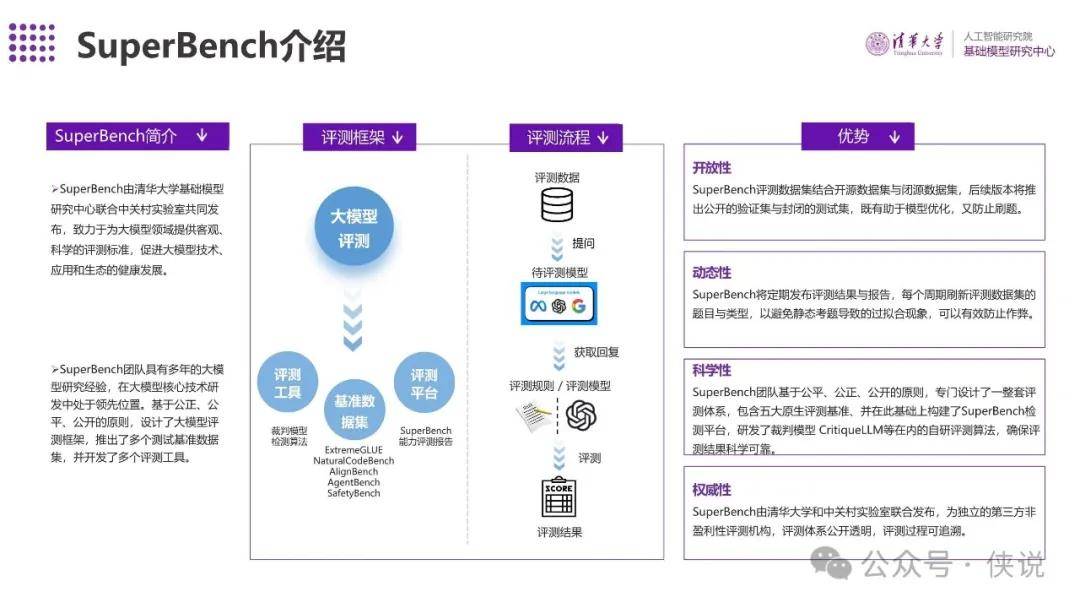
SuperBench介绍
SuperBench评测体系-评测数据集
SuperBench评测体系-语义理解能力
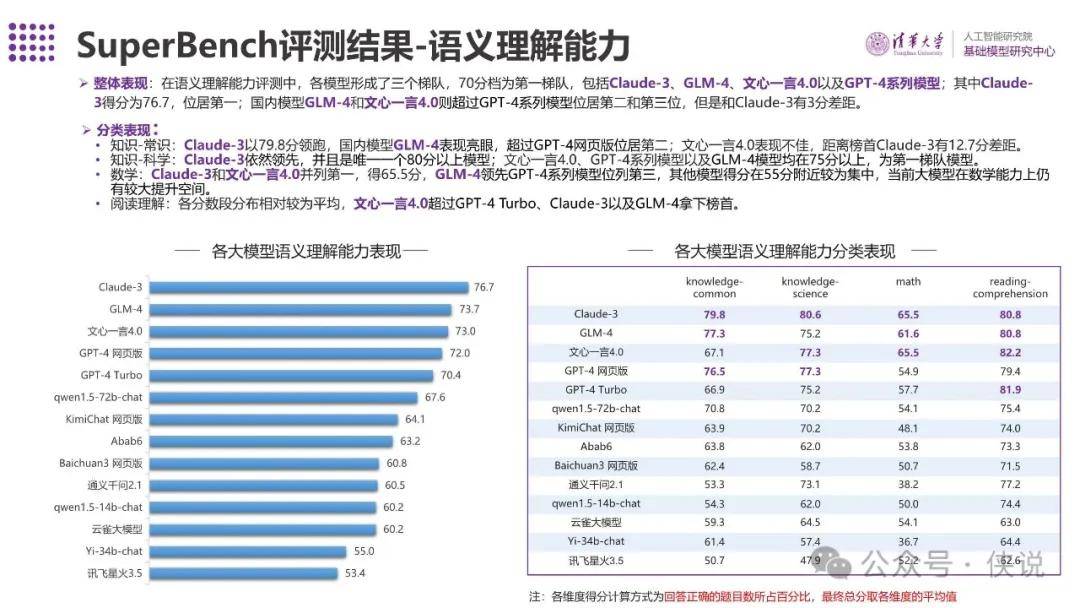
SuperBench评测结果-语义理解能力
SuperBench评测体系-代码编写能力
SuperBench评测结果-代码编写能力
SuperBench评测体系-人类对齐能力
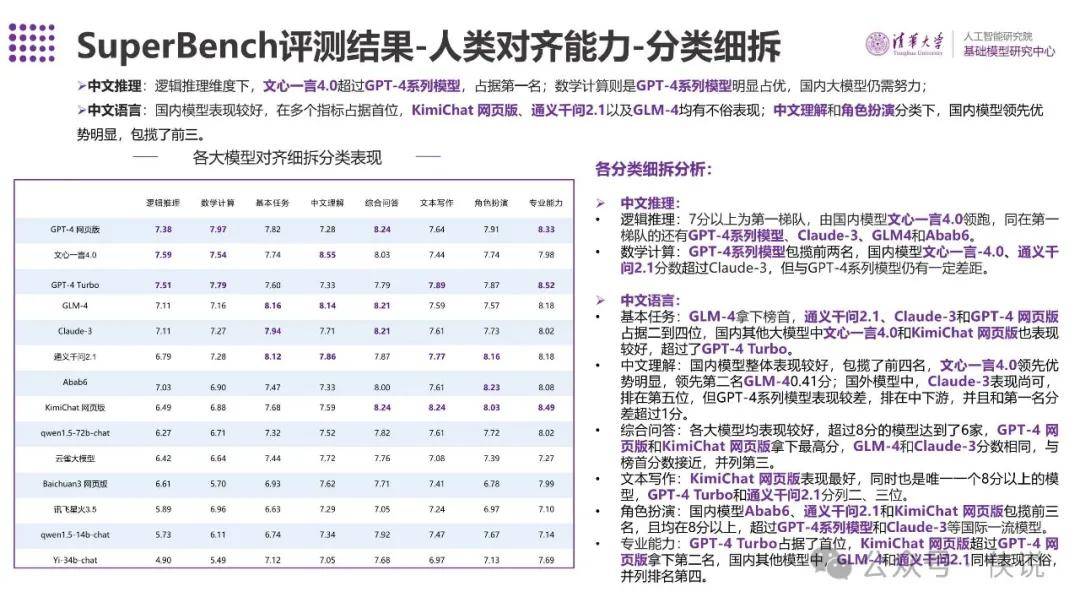
SuperBench评测结果-人类对齐能力
SuperBench评测体系-作为智能体能力
SuperBench评测结果-作为智能体能力
SuperBench评测体系-安全和价值观
SuperBench评测结果-安全和价值观
SuperBench总结
趋势展望:
随着AI技术的不断进步,大模型的能力已成为衡量人工智能发展水平的重要指标。SuperBench的评测报告不仅为我们提供了一个全面的大模型能力评估框架,而且揭示了未来AI技术的发展趋势。
在语义理解方面,模型的对齐程度和指令遵循能力是关键,这将直接影响到人机交互的自然度和效率。代码编写能力的评测结果表明,尽管当前模型在逻辑推理上表现出色,但在代码生成的准确性上仍有提升空间。智能体能力的表现揭示了AI在多任务执行和复杂决策上的巨大潜力。安全和价值观的评测则提醒我们,在追求技术进步的同时,必须确保AI的道德和法律边界得到尊重和维护。
展望未来,我们期待大模型能够在保障安全性和伦理性的基础上,为各行各业带来更多创新和变革。
本报告内容节选如下: